
Geschäftsprozesse klassischer, wie digitaler Geschäftsmodelle sind direkt abhängig von der Datenqualität eines Unternehmens. Schlechte Datenqualität betrifft den klassischen Produktionsbetrieb genauso, wie die digitalen Pilotprojekte vieler Unternehmen. Trotzdem messen nur 40% der Unternehmen die Kosten mangelnder Datenqualität. Bereits 2017 kam eine amerikanische Studie zu dem Ergebnis das schlechte Datenqualität Unternehmen 15-25% des Unternehmensergebnisses kosten. Gleichzeitig zeigt die Studie, dass Unternehmen zwei Drittel der Kosten für schlechte Datenqualität einsparen können. 1
Bewertung von Datenqualität
Wir messen und bewerten die Datenqualität mit allgemein gültigen Kriterien. Diese Kriterien sind nicht unbedingt selbsterklärend, sollten aber herangezogen werden, um den Aufwand und Nutzen von Maßnahmen zur Verbesserung Datenqualität einzuschätzen.
Im Folgenden möchte ich diese Kriterien anhand von einfachen Beispielen näher erläutern und für das Thema sensibilisieren.
Vollständigkeit
Wir messen, ob die Attribute eines Datensatzes vollständig gefüllt sind. Attribute beschreiben den Datensatz. Der Datensatz Kunde wird durch die Attribute Vorname, Name, Straße, Hausnummer, PLZ, Ort, E-Mail Adresse beschrieben. Fehlt der Ort, ist der Datensatz nicht vollständig.
Relativ einfach verbessert – Datenbanken können regelmäßig mit SQL Abfragen geprüft und die unvollständigen Datensätze zur Bearbeitung selektiert werden (per regelmäßigem Job/Automatismus).
Eindeutigkeit oder auch Dubletten
Beschreiben Datensätze denselben Sachverhalt? D.h. ist jeder Datensatz eindeutig interpretierbar?
Beispiel: zwei Kunden haben denselben Namen, die gleiche Anschrift unterscheiden sich aber bei dem Geburtsdatum. Man darf davon ausgehen, dass es sich um Dubletten handelt – aber wann versende ich nun die E-Mail mit dem Rabattcode zum Geburtstag?
Richtigkeit
Haben Sie einmal die Nachnamen Ihrer Kunden geprüft? Wenn zum Beispiel 20% Ihrer Kunden Mustermann heißen, dann hat Max das eBook ziemlich oft heruntergeladen 🙃
In der Praxis werden Datensätze plausibilisiert, beispielsweise schaut man, ob die Daten innerhalb eines bestimmten Wertebereich liegen.
Schwierig sind zum Beispiel Attribute, wie das Geburtsdatum. Während man die Datensätze 1.1.1900 noch leicht filtern kann, bedeutet der 1.1.2004 nur, dass der Kunde älter als 18 Jahre war.
Werden Anwender zur Eingabe von Pflichtfeldern gezwungen, führt das eventuell auch ins Gegenteil. Anwender:innen kennen z.B. das Geburtsdatum nicht und tippt irgendein Datum ein – auch bei Unternehmenssoftware, wie ERP und CRM Systemen.
Aktualität
Idealerweise sind alle Daten zu “heute” auch tatsächlich aktuell. Das gilt für die Abwicklung von Geschäftsprozesse, das Adressieren von Rechnung und bei der Durchführung von Marketing- und Vertriebskampagnen.
Nutzen Self-Service Portale, Single-Point-of-Truth und Co nichts mehr, müssen zur Überprüfung meist externe Quellen und Dienste, wie Melderegister und Co herangezogen werden.
Genauigkeit
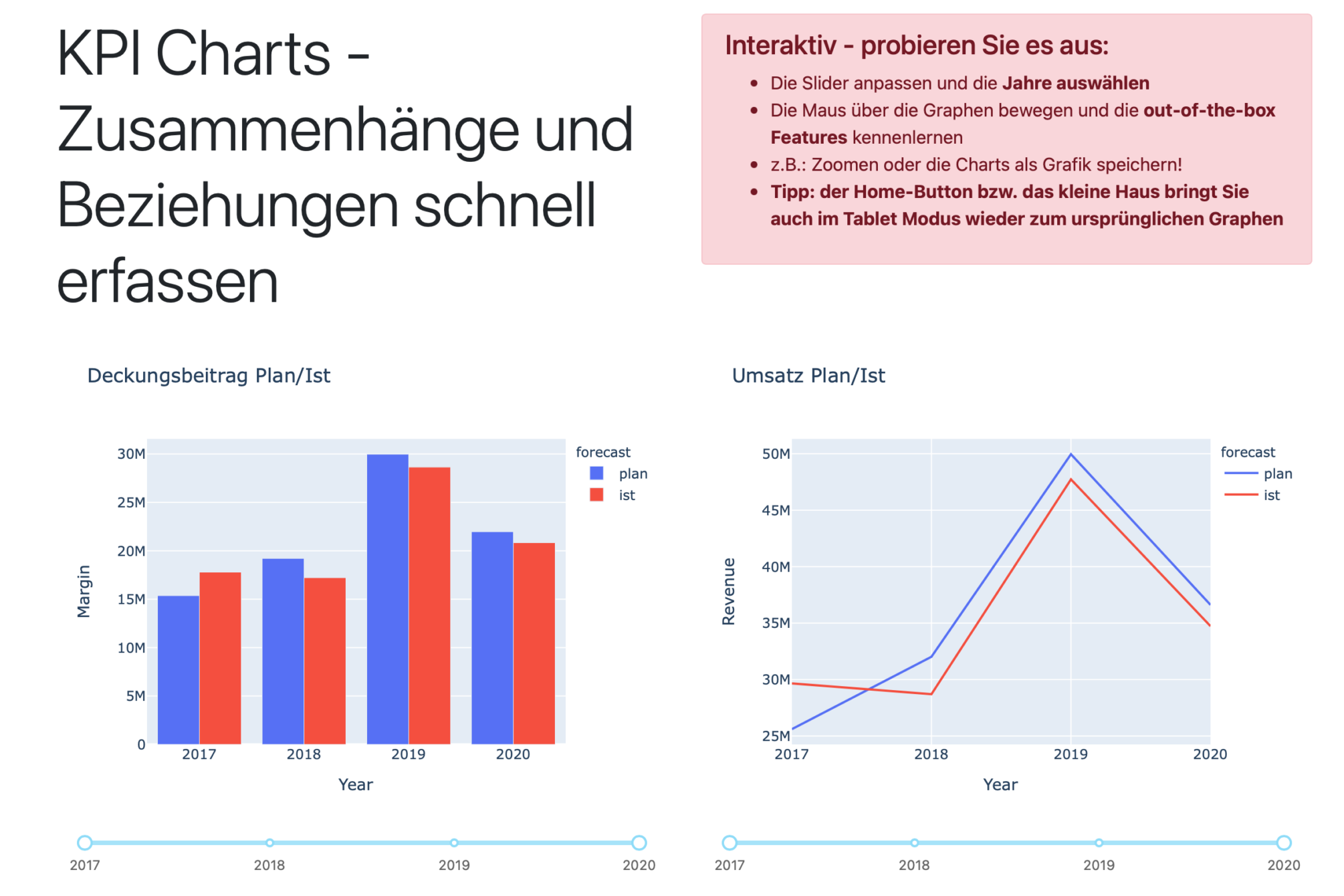
Definition: Daten müssen in der geforderten Exaktheit vorliegen. Am Beispiel von numerischen Werten, wie KPIs – die Kennzahl Umsatz soll immer den Punkt als Tausendertrennzeichen und das Komma mit zwei Nachkommastellen aufweisen. Ob diese Regel über alle Datensätze eingehalten wird, wäre zu prüfen. Es sollte sich aber aus der jeweiligen Felddefinition der Datenbank ableiten.
In der Praxis (und vor allem bei der Einführung oder der Modernisierung von Software) stellt sich das Thema häufig anders dar. In der Datenbank sind u.a. für numerische Felder eine Reihe von „Formatierungsregeln“ definitiert. Speichere ich Daten werden z.B. Werte mit vier Nachkommastellen “übersetzt” (= z.B. gerundet).
Anders verhält es sich wenn Excel mitspielt, dann wird die Zahl im CSV durch Excel interpretiert und beim “Speichern als…” werden Punkt und Komma vertauscht. Der Anwender bemerkt es nicht, schickt die CSV Datei auf die Reise zur Datenbank und zack 100X mehr Umsatz.
Bei internationalen Projekten tritt dieses Problem noch häufiger durch die lokalen Formateinstellung im Excel auf!
Tipp aus der Praxis: Schnittstellen immer, immer(!!) auf granularen Ebenen und einzelnen Datensätzen testen. Bei komplexeren Themen fallen solche Fehler vielleicht zu spät auf, wenn z.B. die modernisierte Schnittstelle nur einen sehr kleinen Teil der aggregierten Daten – auf die Anwender:innen beim Test schauen – ausmacht.
Redundanzfreiheit
Die Datensätze innerhalb einer Datenbank (bzw. über mehrere Datenbanken) sollen nur einmal vorkommen.
Speziell, wenn Daten aus mehreren Quellen zusammengeführt werden, treten immer wieder Überschneidungen und Dubletten auf – aus unterschiedlichsten Gründen.
Relevanz
Einfachstes Beispiel: ich möchte Quartalszahlen ermitteln und von den x Rechnungen, die in Q1 eingegangen sind, ist ein bestimmter Prozentsatz gar nicht relevant, weil es z.B. Geschäftsvorfälle aus dem vergangenen Jahr sind.
Die Relevanz der Daten ist also eher ein wichtiges Kriterium bei der Selektion von Daten für Reporting und Analysen.
Einheitlichkeit
Häufig gibt es bei Unternehmenssoftware keine Validierung (oder Auto-Vervollständigung) der eingegeben Daten. Es werden Tippfehler gemacht, Abkürzungen genutzt und unterschiedliche Sachverhalte abgebildet.
Kleiner Test gefällig. Nehmen Sie die Tabelle Kunde und selektieren das Feld Ort. Dann zählen Sie die unterschiedlichen Schreibweisen von Frankfurt, Frankfurtt, FFM, FRANKFURT,…
Das Problem entsteht u.a., wenn Sie nun im Reporting die umsatzstärksten Städte selektieren wollen, die PLZ aber zu granular ist.
Datenqualität messen und verbessern
Ich hoffe ich konnte anhand der Beispiele für das Thema sensibilisieren. Mit dem Ignorieren von schlechter Datenqualität wird jeden Tag Geld verschwendet! Vor allem wiederkehrende Fehler und deren manuelle Korrektur führen zu erheblichen Aufwänden – korrigieren aber die Ursache für die Datenqualitätsprobleme nicht!
Durch das Messen von Datenqualität in den Datenbanken Ihres Unternehmens, können Sie die „teuersten“ Fehler identifizieren und nachgelagert die Ursachen klären und aufräumen. Die großen Datenbanksysteme von z.B. Informatica und IBM verfügen über Konfigurationsmöglichkeiten umfassender Prüfroutinen.
Bei vermeintlich kleineren Datenbanken und Cloud Software bzw. SaaS Lösungen können Sie sich mit überschaubarem Aufwand, SQL und ggf. ein paar (Python-) Skripten behelfen.
- Seizing Opportunity in Data Quality (MIT Management Report) ↩




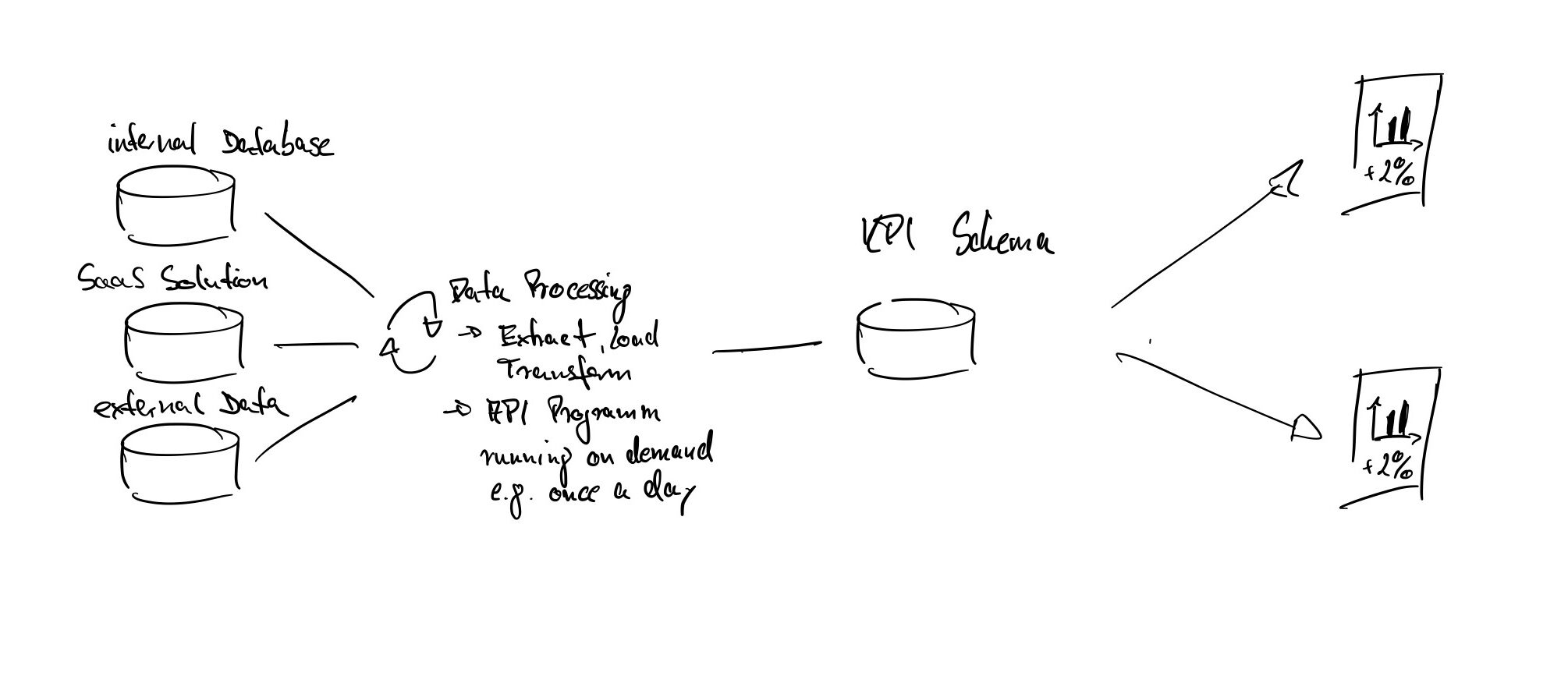
[…] in datengetriebene Entscheidungen. Unternehmen sollten daher Mechanismen etablieren, um die Qualität und Aktualität ihrer Daten kontinuierlich zu überwachen. Parallel dazu spielt die Infrastruktur eine entscheidende Rolle: Eine skalierbare Plattform, die […]
[…] Geschäftsprozesse klassischer, wie digitaler Geschäftsmodelle sind direkt abhängig von der Datenqualität eines Unternehmens. Schlechte Datenqualität betrifft den klassischen Produktionsbetrieb genauso, wie die digitalen Pilotprojekte vieler Unternehmen. Trotzdem messen nur 40% der Unternehmen die Kosten mangelnder Datenqualität. Bereits 2017 kam eine amerikanische Studie zu dem Ergebnis das schlechte Datenqualität Unternehmen 15-25% des Unternehmensergebnisses kosten. Gleichzeitig zeigt die Studie, dass Unternehmen zwei Drittel der Kosten für schlechte Datenqualität einsparen können. 1 […]