Verfügbarkeit von Daten
Die Relevanz von Daten, die Notwendigkeit der Integration verschiedener Datenquellen und die einfache Nutzung der Daten für effiziente Prozesse und wirtschaftlichen Entscheidungen, sollte unbestritten sein.
In den IT Landschaften von Unternehmen finden sich neben Datenbanken und Systemen auf internen Servern – on premise (legacy) Software – zunehmend mehr Software as a Service (SaaS oder allg. Cloud) Lösungen. Egal, wie komplex und ausgefeilt die Lösungen auch sind, irgendwo werden immer wichtige und ggf. sogar geschäftskritische Daten per Datei/Mail ausgetauscht (und im Zweifel über den halben Globus geschickt).
Anwender greifen immer auf die schnellere und einfachere Lösung zurück. Bei der Integration von Systemen und der Bereitstellung von Daten muss die unkomplizierte und schnelle Verfügbarkeit daher gewährleistet sein. Andernfalls bleiben vor allem wiederkehrenden Aufgaben/Tätigkeiten im Regelbetrieb nicht optimal ausgestaltet. Sind Daten nicht kurzfristig (und in richtiger Form) verfügbar und sind die betrieblichen AdHoc Fragestellungen immer wieder mit initialen Aufwänden verbunden, führt das dazu, dass (wahrscheinlich) ein großer Teil dieser Fragestellungen pauschal mit „so wie immer“ bewertet und beantwortet wird.
Meiner Meinung nach effizienter ist die Automatisierung des Regelbetriebs unter Verwendung von praktikablen Standards mit dem Ziel Daten für Fachanwender zur Verfügung zu stellen – ohne regelmäßig x Tage Aufwand zu produzieren!
Die Daten as a Service Architektur
Ich möchte hier kein neues Buzzword prägen, sondern den Ansatz erläutern und bediene mich daher den Marketing-Botschaften der vergangenen Jahre.
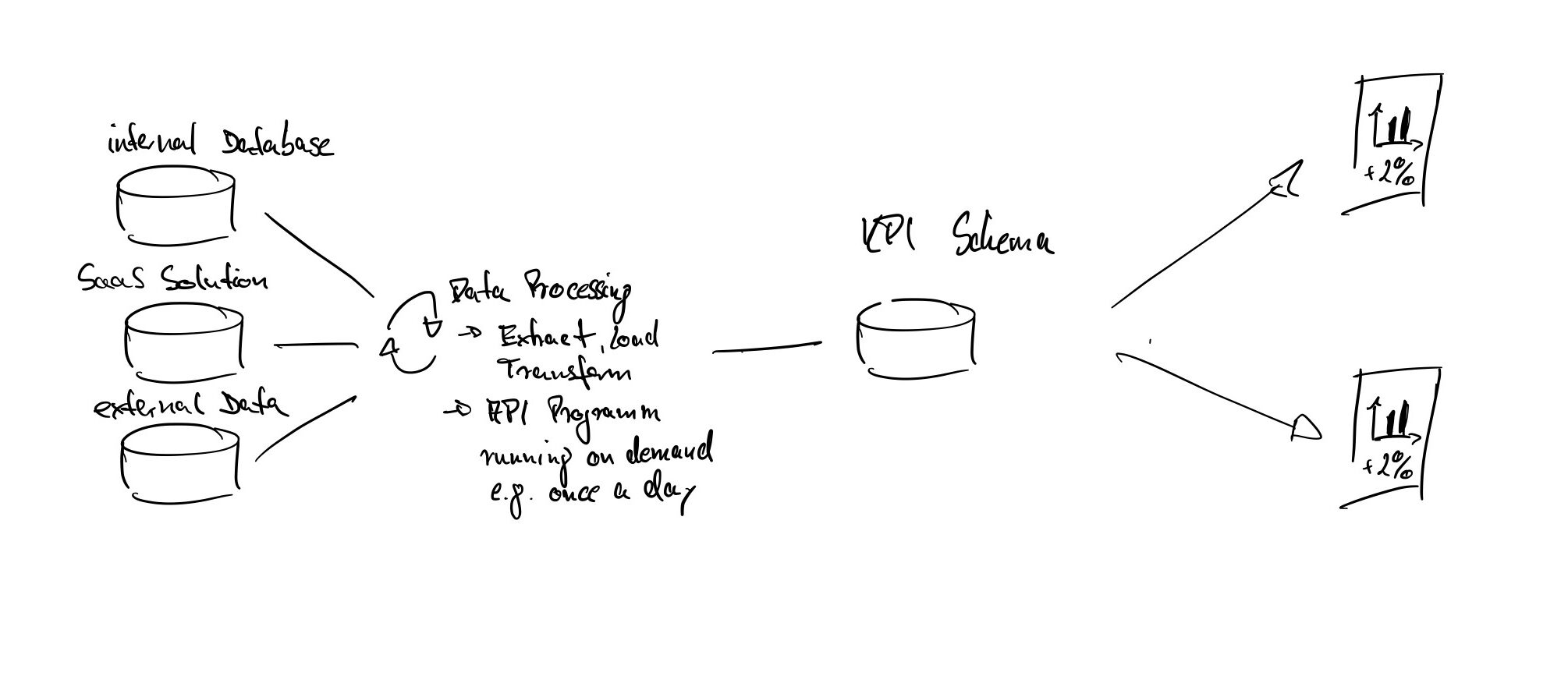
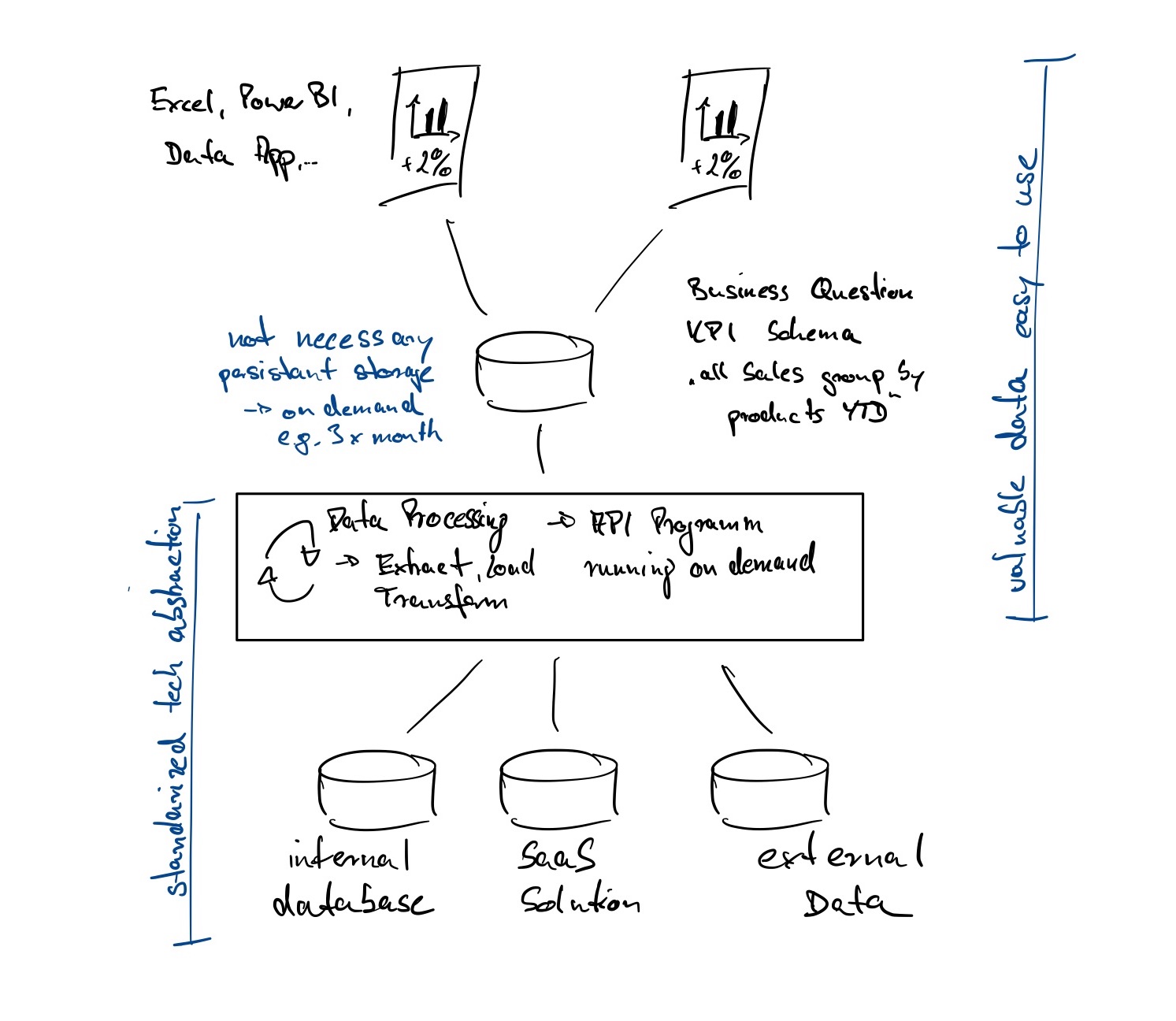
Die Idee: relevante Daten als unkompliziert verfügbarer Service für neue Projekte, aktuelle Ad-hoc Fragestellungen oder betriebliche Routine zur Verfügung zu stellen.
In 3 Schritten:
- Standardisieren wie Daten extrahiert, transformiert und geladen werden – ja, im Grunde klassisches ETL.
- Spezifische Datenpakete (z.B.: „KPIs aller Verkäufe für das Jahr XY sortiert nach Produktgruppen“) für die weitere Verwendung zur Verfügung stellen.
- Umfang und Funktion dieser Services wirtschaftlich sinnvoll auf- und ausbauen.
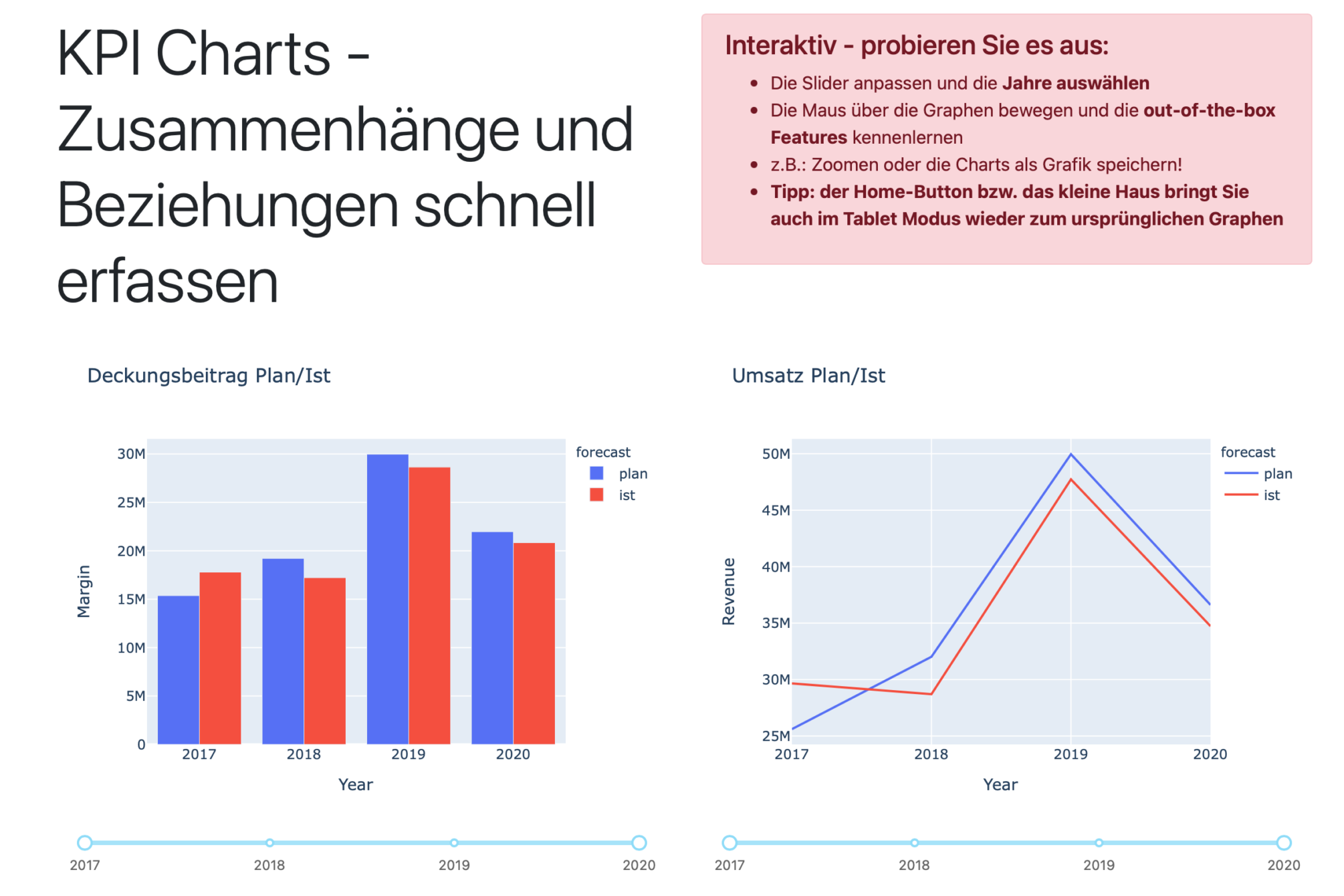
Ein Beispiel: Kurzfristig werden Daten aus zwei Quellsystemen benötigt, um an neuen Maßnahmen zur Kundenbindung zu arbeiten. Dem „Daten as a Service“ Ansatz folgend, stehen die Daten der beiden Quellsysteme über einen standardisierten Mechanismus aktuell aufbereitet den Fachanwendern zur Verfügung. Der Anwender soll zur weiteren Verarbeitung und Analyse verwenden können, was für die Aufgabe gerade am besten passt! Beispielsweise ein Download der Daten als CSV für die Weiterverarbeitung in Excel, der kurze Blick auf das Dashboard vor dem nächsten Budget Meeting oder die tiefergehende Analyse per Analytics Tool, wie PowerBI und Jupyter Notebook.
Wie funktioniert die Demo?
Für die Demo nutze ich eine MySQL Datenbank auf einem virtualisierten Server. Die SQL Tabellen werden innerhalb des „API Daten Layer“ abgefragt, aufbereitet und aggregiert. Die erzeugten Datenpakete können per API Endpoint (eine URL) genutzt werden. Dazu kommen Python und FastAPI zum Einsatz – Serverless per AWS Lambda. Das bedeutet, jedes Mal, wenn einer der Endpunkte abgerufen wird, wird der API Layer gestartet, ausgeführt und liefert die angeforderten Daten zurück.
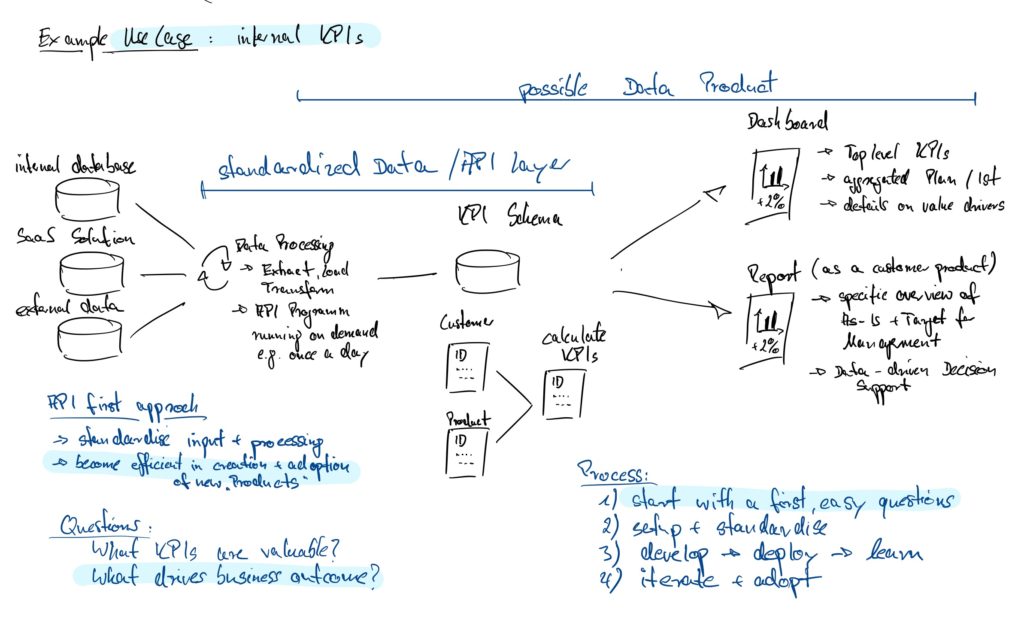
- Kommen weitere Datenquellen hinzu oder wird eine Datenquelle z.B. ersetzt, ist lediglich der API Daten Layer anzupassen und die nachgelagerten Prozesse bleiben unberührt
- Werden die Endpunkte im Zuge neuer Anforderungen erweitert, stehen diese direkt für die Arbeit der Fachanwender zur Verfügung (ohne erneute Integrationen, User Authentifizierungen, etc.)
Wenn Sie den Link zur Demo aufrufen, sehen Sie ein funktionales Dashboard mit einigen Beispielen. Das Dashboard verwendet die API Endpunkte als Datenquelle, d.h. das Öffnen des Dashboards fragt mehrere Endpunkte ab, die Abfrage startet den API Layer und der verbindet sich zur Datenbank, liefert die Daten und geht wieder in den Standby bis die nächsten Daten angefordert werden.
- Daten und Dashboard sind unabhängig voneinander und bleiben austauschbar
- Die im Dashboard visualisierten Daten stehen über denselben Mechanismus weiteren Systemen und Projekten zur Verfügung (Import der Daten in Excel, PowerBI und andere Analytics Tools per CSV oder API-Quelle)
- Datenintegration zwischen internen IT Systemen, Cloud Lösungen und anderen Services
Entwicklung, Wartung und neue Funktionen
IT Landschaften sind über die letzten Jahre nicht übersichtlicher geworden. Kaum waren interne IT Ressourcen an externe Dienstleister verlagert, wurden Teile von Software Lösungen nur noch gemietet und am Ende hat man so viele bewegliche Teile, dass alles irgendwie mit IT zu tun hat und diverse Projekte parallel laufen.
Einen Schritt voraus sein, heißt die Veränderung des Zusammenspiels von IT Systemen zu erwarten und wirtschaftlich sinnvoll zu verwalten. Die (Weiter-) Entwicklung und Wartung einzelner Komponenten sollte von der aktuellen IT-Umgebung entkoppelt sein, so dass Server, Datenbanken und Co. austauschbar bleiben. Praktisches Beispiel: Sie müssen eine alte Datenbank auf eine neue Lösung migrieren, haben dafür eine fixe Deadline, führen aber parallel erste Gespräche, um Teile Ihrer Datenbanken in die Cloud zu schieben, weil Sie z.B. die eigenen Server nicht mehr betrieben wollen. Die Datenbank, die Datenverarbeitung und das Dashboard können innerhalb kurzer Zeit auf andere Server umziehen, bei anderen Cloud Providern laufen und dazu reicht ein Laptop mit Internetzugang.
Datenintegration muss nicht komplex sein
Der Aufbau und Betrieb von großen Datenplattformen ist ein strategisches Investment. Der kurz- bis mittelfristige wirtschaftliche Nutzen rechtfertig selten große IT Projekte, aber IT Projekte für Datenintegration müssen eben nicht immer „groß“ sein. Standardisierung der Datenanbindung und -aufbereitung, wie in der Demo, reduziert den Aufwand für künftige Projekt, bleibt aufgrund des Betriebsmodells flexibel und kommt ohne neue Software-Lösungen und Vendor Lock-in aus.
So geht’s:
- Aktuelle und potentiell zukünftige Anforderungen klären.
- Grundsätzliche IT Landschaft und standardisierte Lösung skizzieren.
- Bei der Umsetzung der ersten kleinen Projekte lernen und die Lösung ausbauen, verbessern und flexibel bleiben.
Sie suchen Unterstützung für Ihr IBM Planning Analytics TM1 Projekt?